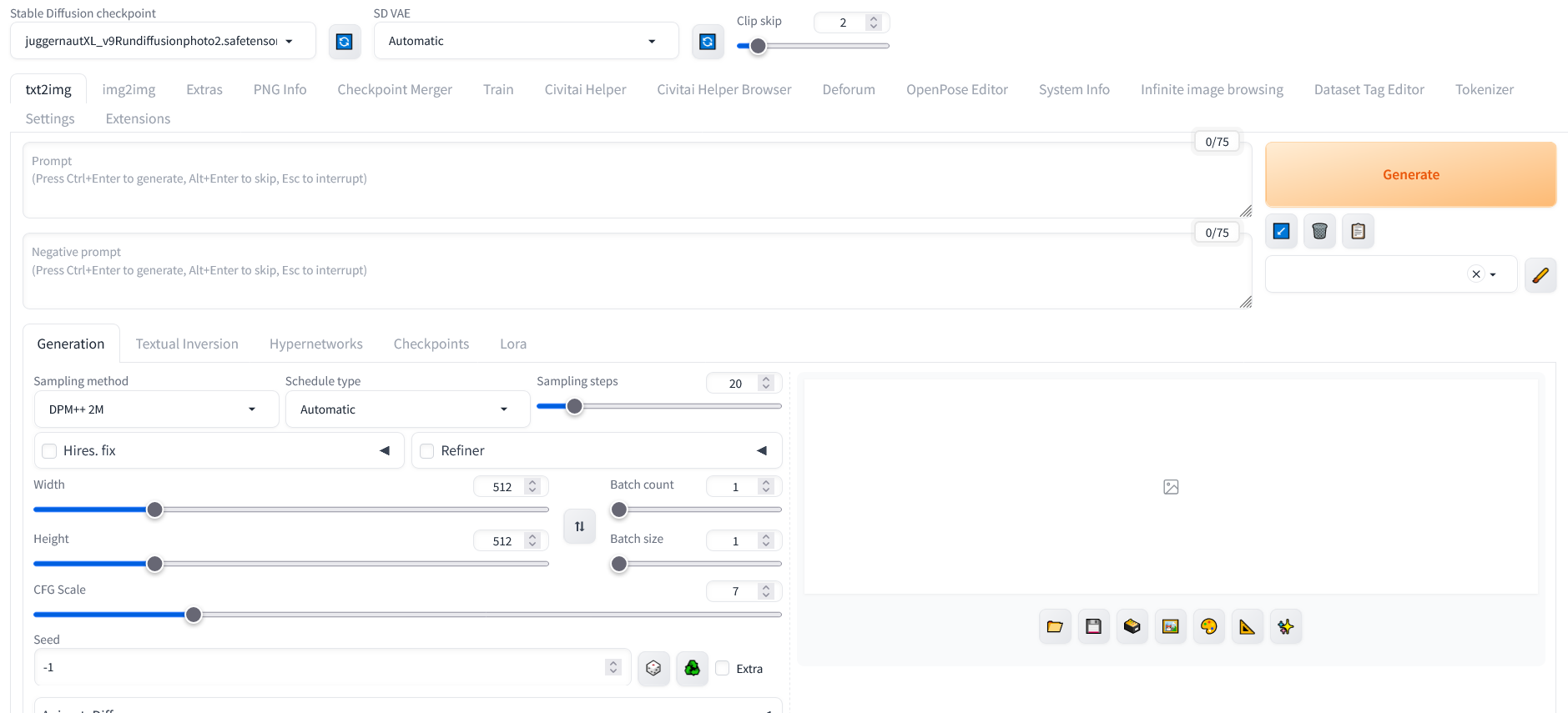
Si vous avez une machine qui dispose d’au moins 8gb de VRAM, vous pouvez essayer de générer des images grâce à l’intelligence artificielle sur votre propre ordinateur.
Je vais ici vous présenter les concepts importants pour débuter.
Les 3 logiciels :
Automatic1111 : https://github.com/AUTOMATIC1111/stable-diffusion-webui
Le plus populaire à l’heure actuelle.
Forge UI : https://github.com/lllyasviel/stable-diffusion-webui-forge
Une réplique modifiée de Automatic 1111 qui voit sa popularité augmenter depuis qu’il permet d’utiliser les modèles FLUX
ComfyUI : https://github.com/comfyanonymous/ComfyUI
Moins utilisé, car plus technique
J’utilise ici Automatic 1111 avec une carte 3060RTX 12Go
Des concepts importants :
Text2img : L’images est générée à partir d’un prompt.
Img2img : L’image est générée à partir d’une image de référence.
Inpainting : On donne un prompt pour modifier une partie d’une image existante.
Prompt : Les instructions données au modèle.
Negative Prompt : Les instructions de ce qu’on ne veut pas.
Upscaling : Filtre qui permet de grandir la résolution du résultat
Les modèles (Checkpoint) :
Il existe des modèles de base (sd 1.5, sd XL, FLUX etc.), mais aussi une multitude de modèles retravaillés par la communauté.
Certains modèles sont spécialisés en réalisme, d’autres en cartoon, etc. Il suffit de télécharger un modèle et de le placer dans le répertoire adéquat de votre logiciel pour pouvoir l’utiliser.
Attention aux licences !! Chaque modèle a sa licence d’utilisation …
Attention : La taille du modèle ne doit pas dépasser la taille de la mémoire de votre carte graphique !
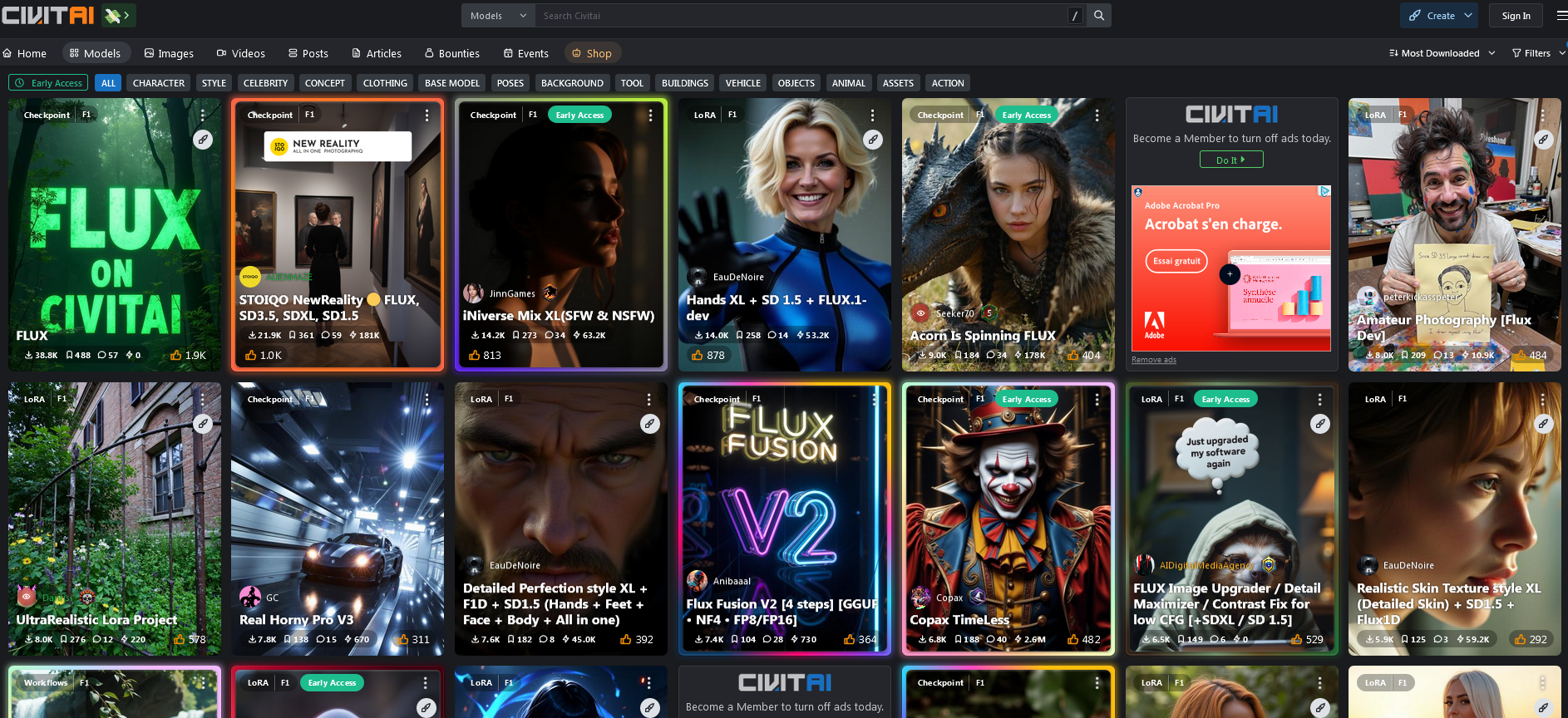
Une bonne source de modèles se trouve ici : https://civitai.com/models
SD 1.5 : C’est le modèle de base de « stable diffusion » qui est rapide et est encore largement utilisé du fait des nombreux « LoRA » et autres filtres apportés par la communauté.
SDXL 1.0 : C’est le modèle qui a succédé à SD 1.5, plus orienté réalisme.
FLUX : Un modèle encore meilleur, mais qui ne fonctionne (pour l’instant) que sur Forge UI et Comfy UI.
LoRA : Un LoRA (Low Rank Adaption) est un petit modèle entrainé sur un point précis. Un personnage, un style, un concept etc. Les LoRA sont appelés dans vos prompts pour ajouter des effets.
Textual Inversion & Embeddings : Comme les LoRA, mais encore plus petits. Ils ajoutent des corrections comme par exemple les mains avec trop de doigts .
VAE : Ajoute des détails et des corrections d’images à la fin du processus.
Des extensions :
ControlNet (essentielle ! ): Une extension qui va par exemple permettre de définir des poses des personnages. Vous trouverez facilement une multitude de tutoriels sur le sujet.
ADetailer /DeForum : Des filtres et des outils.
ESRGAN : Permet de faire de l’upscaling de bonne qualité pour atteindre de grandes résolutions.
AnimatedDiff : Permet de générer de courtes vidéos, souvent sous forme de GIF animés.
Vous voilà prêt pour votre premier prompt !
Attention : tous les prompts sont en anglais
Un exemple : « Portrait of a woman from the Alpes in 1920s. Alpes mountains in background. »
Modele : juggernautXL_v9Rundiffusionphoto2 (base sdxl 1.0)

Même prompt avec le modèle « realcartoon25D_v3 » (base sd1.5), spécialisé Dessin à plat.


Enfin, la même chose avec FLUX (modèle acornIsSpinningFLUX_aisFluxDeDistilled) :


Vous pouvez voir les différences énormes d’interprétation selon les modèles, sur un prompt identique.
Quelques petites choses importantes :
- Le temps mis pour générer une image va dépendre de la capacité de votre carte graphique, du modèle utilisé, de la taille de l’image voulue, du nombre de Steps (itérations, généralement 20) configuré. Cela va de quelques secondes à plusieurs minutes !
- Cela consomme de l’énergie ! Votre carte graphique et votre CPU seront utilisés presque au maximum de leurs capacités.
- On génère habituellement beaucoup d’images d’un coup, pour ensuite faire une sélection.
Il est temps d’essayer ! A vous de jouer !