Il est possible d’entrainer le LoRA d’une personne… Cela signifie qu’il est alors possible de générer des photos de cette personne dans tous les contextes possibles et imaginables.
La question sous-jacente, sous prétexte d’un titre aguicheur, est celle du droit à l’image et même peut-être plus.
Le TOP 10 du mois (novembre 24)
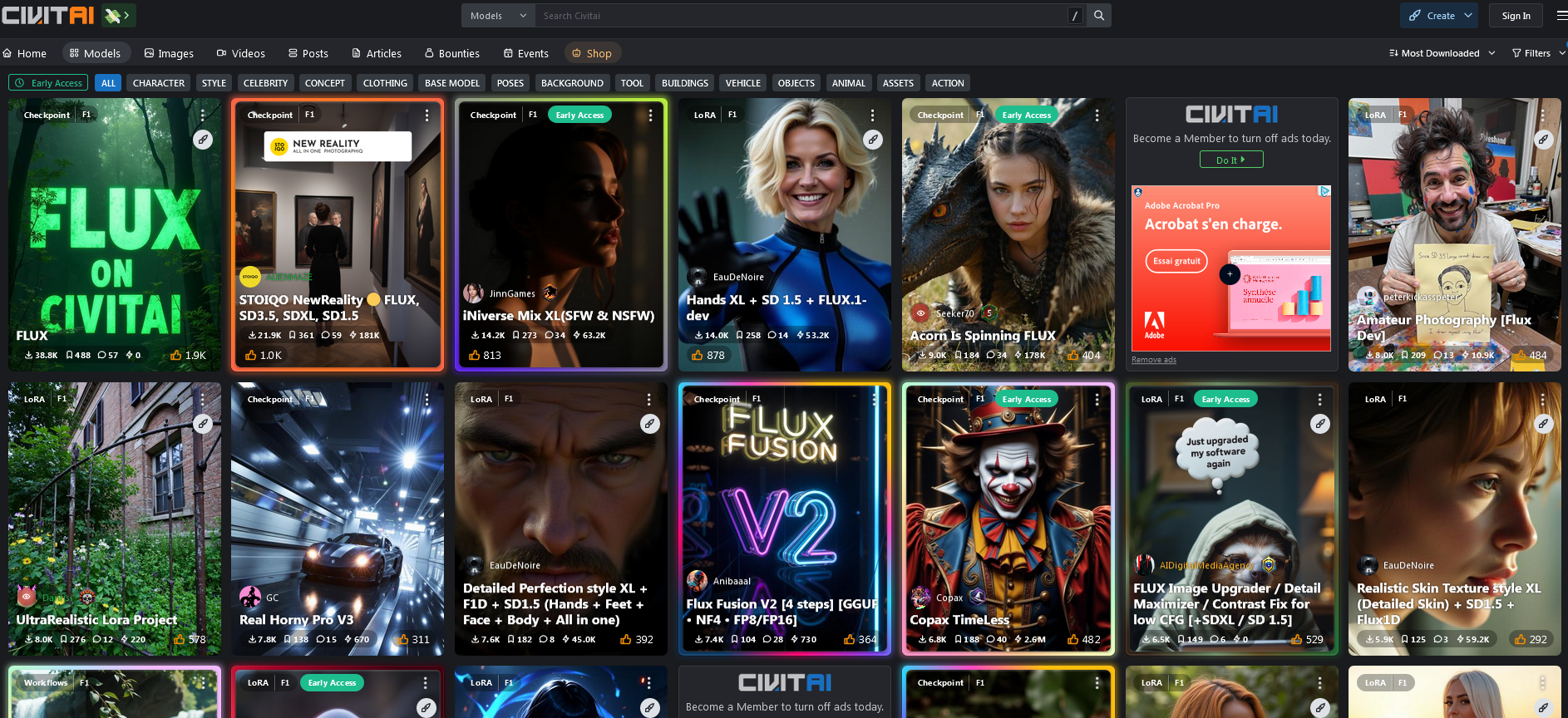
Le filtre : Les LoRA « célébrité » les plus téléchargés sur les 30 derniers jours. Uniquement sur le modèle FLUX (ultra-réalisme).
https://civitai.com/models?tag=celebrity
Vous pouvez indiquer day/week/month dans « filter » en haut à droite
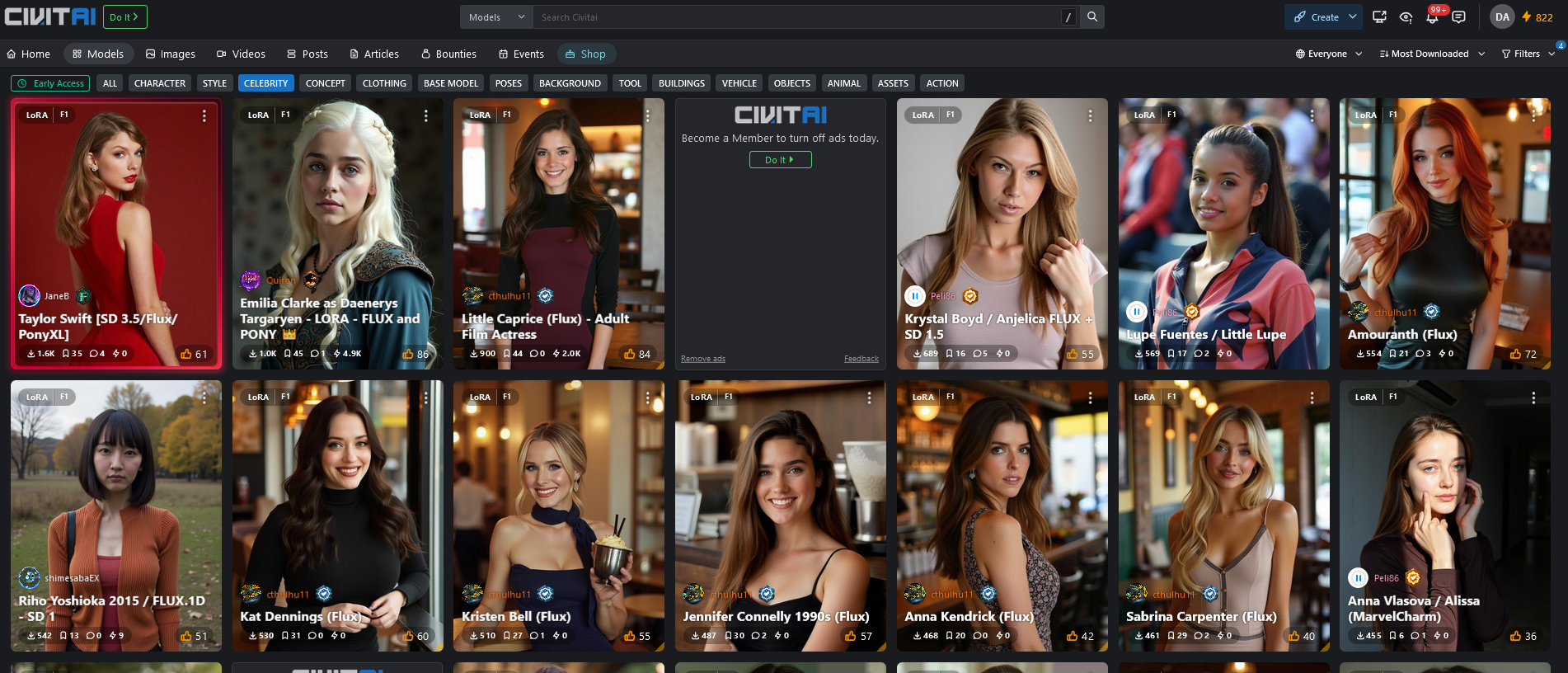
Notez qu’aucunes des images n’est une vraie photo de la célébrité …
Dans l’ordre :
- Taylor Swift (chanteuse)
- Emilia Clarke (Daenerys dans Game of Thrones)
- Little Caprice (actrice films adultes)
- Krystal Boyd (actrice films adultes)
- Lupa Fuentes (actrice films adultes)
- Amouranth (streameuse célèbre sur twitch)
- Riho Yoshioka 2015 (actrice japonaise)
- Kat Dennings (actrice américaine)
- Kristen Bell (actrice américaine)
- Jennifer Connely 1990s (actrice américaine)
Le 1er homme est Donald Trump autour de la 60e place.
La 1ere française est Eva Green autour de la 100e place.
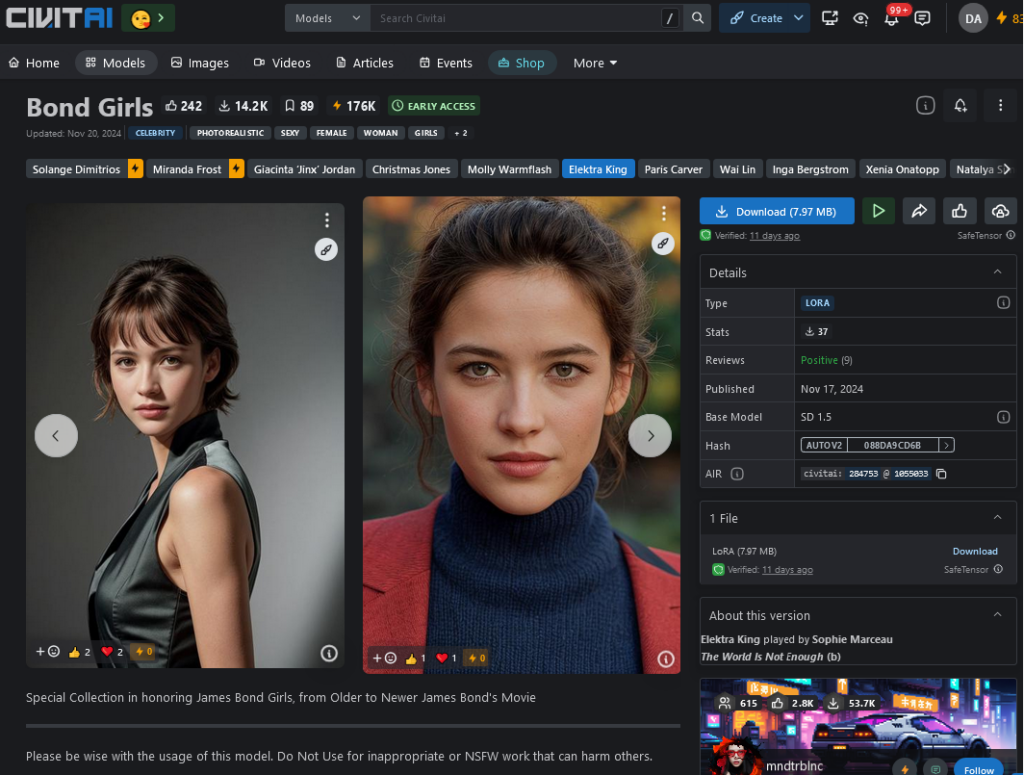
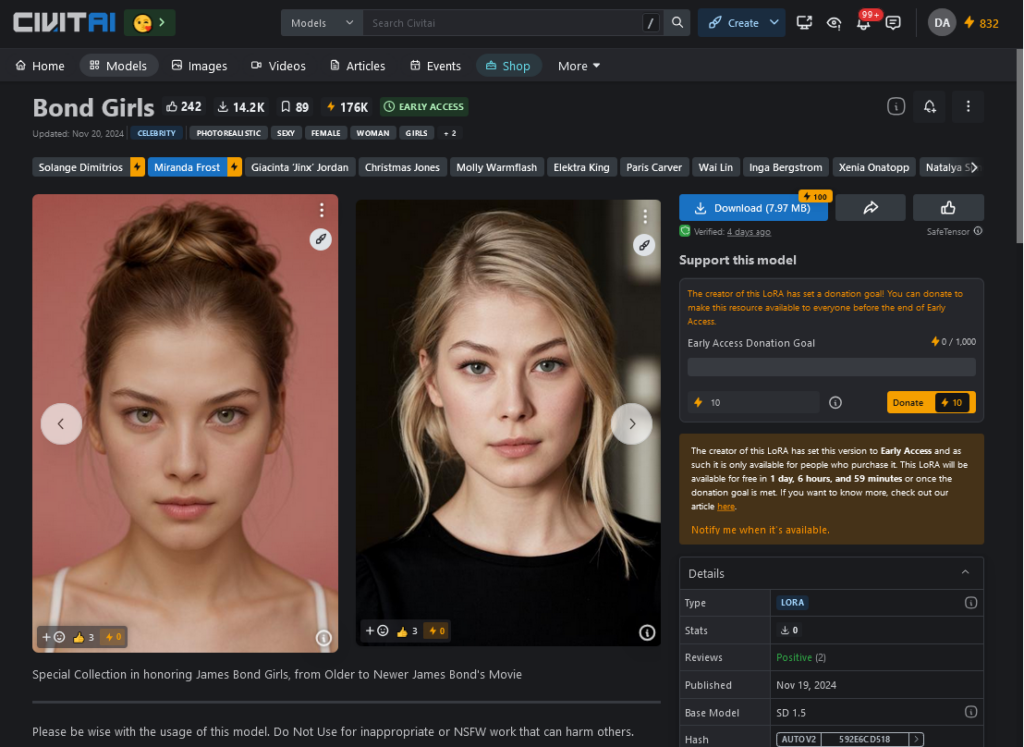
James Bond Girls : https://civitai.com/models/284753?modelVersionId=1055033
Sur l’année, et tous les modèles confondus:
- Tous les acteurs de Game of Thrones
- Les James Bond Girls
- Aespa Karina (chanteuse Sud-coréenne)
- Emma Watson (Hermione)
- etc.
Inutile de chercher à analyser les pourquoi de ce classement, pourquoi ces célébrités et pas d’autres, tout le monde aura bien compris, et ce n’est pas le sujet.
C’est toi, oui, mais quand ?
Et oui ! Nous changeons… le temps fait son œuvre. C’est la première chose qui m’a frappé : Ce ne sont pas des LoRA de la personne, mais de la personne à une époque précise, ou dans un contexte précis (un film), à une époque où les photos d’entrainement (dataset) sont cohérentes.
L’exemple le plus parlant est le LoRA de « Erin Moriarty Pre-plastic surgery ». Autrement dit, c’est le modèle de cette actrice américaine « avant qu’elle ne se fasse refaire le visage ». Ou pour Jennifer Connely, il est bien spécifié que l’entrainement est basé sur des photos d’elle dans les années 1990.
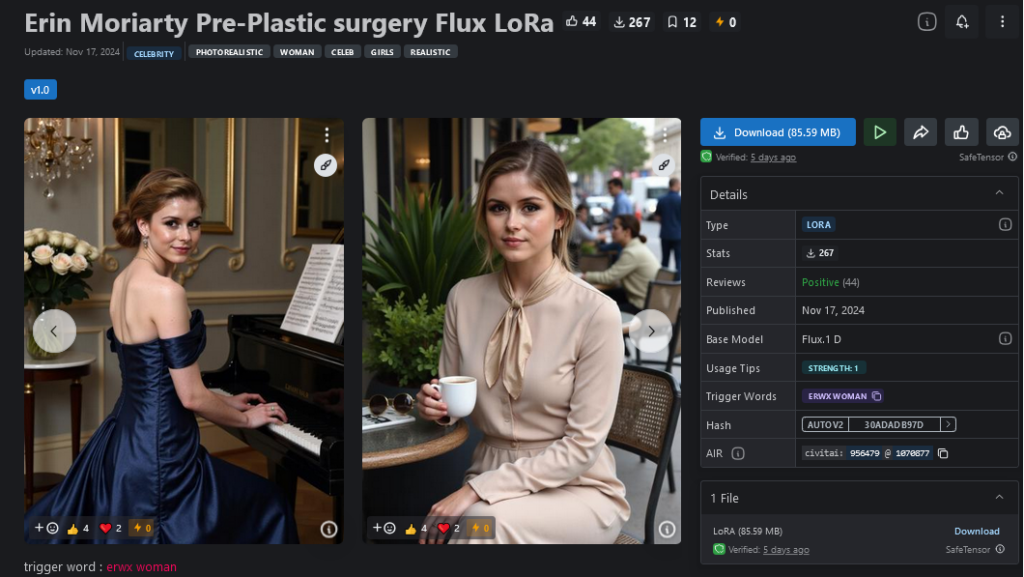
Ce qui m’intéresse ici, ce n’est pas que des fans veuillent générer leur idole à des âges différents, mais c’est l’idée que la personne elle-même (ou sa famille) puisse générer ces images d’un temps qui n’est plus… « Regarde, je me suis fait une photo de moi avant… »
Mais imaginons que bientôt il soit pertinent/possible de générer des LoRA d’une personne à travers les âges. Il suffirait alors d’indiquer dans le prompt l’âge de la personne en question pour retrouver une image fidèle et réaliste.
Puis, bientôt (déjà là), des vidéos, avec une reproduction de la voix…
Plus loin, je peux facilement imaginer un écran posé sur une table avec dedans « l’avatar » vidéo et sonore de mon grand-père qui puisse m’écouter et me répondre grâce à un chatBot. Ce ChatBot étant optimisé sur l’ensemble des souvenirs écris et numérisés de mon grand-père (par un RAG sur le LLM).
Est-ce un bien ou un mal ? Je ne le sais pas. Mais toutes les technologies sont déjà là.
Changeons de point de vue
Quel est le principe d’un LoRA ? Et de l’IA en général ?
Le principe est de numériser le sens (humain) des choses, extraire l’équation de la chose. En philosophie, on parlerai de « l’essence » et d’un processus « phénoménologique ».
Un LoRa est l’expression numérique de ce qui fait que cette « chose » est différente des autres « choses », l’ensemble de ses caractéristiques nécessaires qui font que, pour tout humain, cette chose est percevable et identifiable en tant que telle. Cette version numérique est associée à un mot clef. L’utilisation de ce mot clef dans un prompt va donner des contraintes au modèle lors de la génération.
Mais cet entraînement est nécessairement imparfait. La meilleure preuve en est que sur certaines célébrités, il y a plusieurs versions de LoRA disponibles.
Le LoRA est une interprétation de celui qui a fait l’entrainement par un choix des photos du dataset. Cela va en déterminer l’orientation, les accents, la qualité.
Aussi, et c’est là où je voulais en venir, l’utilisation d’un LoRA est, a priori, aussi soumise à des droits… Il n’est pas seulement dépendant des photos/matériels utilisés, mais aussi directement déterminé par un auteur qui a fait des choix. Cela ne m’étonnerait pas que, rapidement, des LoRA deviennent payants, ou, aussi, deviennent des supports marketing…
Notez que même si on reste dans un usage strictement personnel, car je ne pense pas qu’un professionnel s’amuserait à générer des images de quelqu’un sans son consentement, certains auteurs de LoRA font preuve d’une certaine déontologie en rappelant : » Please be wise with the usage of this model. Do Not Use for inappropriate or NSFW work that can harm others. »
Conclusion
Il y a quelque chose de profondément nouveau dans cet étalage de personnes à télécharger, qu’elles soient célèbres ou non.
En effet, il est possible de télécharger par exemple toutes les princesses Disney… Mais aussi des personnes « nobody », autrement dit des personnes communes, « quelqu’un », l’homme de la rue.
Bientôt des services de recomposition de personnes à partir de toutes ses photos, vidéos et écris dont on dispose sur elle ?
Il y a quelque chose de l’ordre du « vol d’âme ». On n’est plus dans le simple montage photo, on a passé un cap…
Il y a, je pense, ici un pouvoir potentiel de nuisance à la personne énorme, mais aussi de potentiels bienfaits enthousiasmants.
Mon grand-père sur une clef USB ?…
Ce sont de vraies questions qui s’avancent.
Références :
Prompt de l’image en une : <lora:nobody_2_f1:1> The image is a portrait of a young woman sitting in the back seat of a car. She has long, wavy blonde hair that is styled in loose curls and falls over her shoulders. She is wearing black-rimmed glasses and has freckles on her face. The woman is looking directly at the camera with a serious expression. The background is blurred, it’s ALpine mountains near Chambéry – Savoie, but it appears to be the interior of the car, with the sunroof visible on the right side of the image. In the bottom centered of the photography is text written in the VHS timestamp style « NOBODY – NOV 2024 «
LoRA « Nobody : https://civitai.com/models/675026/flux-nobody-model